I am using the following code snippet to find counts of each words in one list box, and putting the results in a second listbox.
(For example: list 1 may have (as a LIST) "Now, Is, The, Time, For, Now, Time, Good, Now"....list 2 would end up with "Now-3, Is-1, The-1, For-1, Time-2, Good-1) -Where the numbers are the number of occurrences of each particular word.
Working with 'small' word counts (500 or so), it goes pretty rapidly (< a second).
But when I increase the word count, say to over 10,000, it slows down to a CRAWL (minutes).
Any suggestions/better&faster way to do this?
Code:
Private Sub poplist2()
List2.Clear
Dim MyArray() As String, CountOccurance As Long
Dim i As Long, j As Long, k As Long
k = 0
Do While k < (List1.ListCount - 1)
For i = 0 To List1.ListCount - 1
If LCase(List1.List(k)) = LCase(List1.List(i)) Then _
CountOccurance = CountOccurance + 1
Next i
ReDim Preserve MyArray(k + 1) As String
MyArray(k) = LCase(List1.List(k)) & "-" & CountOccurance
CountOccurance = 0
k = k + 1
Loop
For i = LBound(MyArray) To UBound(MyArray)
List2.AddItem MyArray(i)
Next i
Dim totListItms As Double
totListItms = List2.ListCount - 1
Do While totListItms >= 0
For i = totListItms - 1 To 0 Step -1
If LCase(List2.List(i)) = LCase(List2.List(totListItms)) Then
List2.RemoveItem i
totListItms = totListItms - 1
End If
Next i
totListItms = totListItms - 1
Loop
End Sub
I think that entire routine can be sped up immensely by using API: SendMessage and LB_FINDSTRINGEXACT
That API would remove your inner loops that iterates thru the listbox. If you search the forum for LB_FINDSTRINGEXACT, you should find good examples.
Out of curiosity, why is totListItms declared a double? It has to be converted by VB to a Long or Integer at least once for each iteration in the last loop
Insomnia is just a byproduct of, "It can't be done"
@dile....roger....gonna change that to an array.
@LaV...I'll give the API a shot.
...TotListItms probably should be an Int. (will try this part first).
You could also speed it up by not using the redim preserve in the loop.
Would be faster to have a larger array than needed to start with and then if needed reduce the size after the loop has finished so you have only one call to redim preserve rather than several.
Another thing is that if the same word occurs more than once your code is going to process that word more than once which would both give undesired results and slow it down a good bit, especially so with that redim preserve in there
One more thing after looking it over again, your loop is going to run until k = listcount so there is yet another reason to use the redim above the loop and set the boundry to listcount or listcount-1 as needed.
I think if I were going to try this using a listbox the first thing I would do is sort the listbox.
I would create a variable that holds the last value read from the list which would of course start out as an empty string.
I would then loop through the list comparing the value just read to the lastvalue var.
If they are the same then increment the counter var by 1
If they are different write the lastvalue and the counter to the other list, or the counter to an array if that is what you need, set the lastvalue to the current value, set counter back to 1 and continue the loop. If using an array to store the count of each word I would redim that array before the loop to the size of the list I am reading
After the loop resize the array to the size of the second list, or not bother to resize it after the loop depending on the needs.
This method should give better results and should be a LOT faster than what is in the OP
thx, DM....probably won't get back to this little project until Monday, but yes, I currently have both lists 1 and 2 sorted.
Will be trying all three major suggestions above, but the weekend is nearing!!!! So, will revisit on Monday.
I give my thought here, not a single line of code.
Every word in a dictionary can be simplify like this "like" to be "li" and "ke". So We can use an array of 1000 strings in a shorted array (using an index array for swapping indexes) for two letters first part of a word and a second array for three letter "the", "thi". So we give a second row for that arrays where we put actual tokenized words but from second part of the word except for some numbers that means ...no other part, only a letter, and two more guards the &hffff and &hfffe. So in any string we put a guard, tokens, the second guard and an integer number as char (2 bytes).
So for finding "probaly" we have to break this in three parts, "pro","ba","ly", found the tokens, and went to "pro" second row, make the search string with the one guard plus two tokens (so 3 chars in unicode) plus second guard and find the position, or not. If not then we add the search string plus a charW(1). If we found it in position X then we add the len of the search string and we have the char where we increase the number.
We have a fault if we have a word more than 65534 times...
Last edited by georgekar; Dec 19th, 2014 at 03:16 PM.
I give my thought here, not a single line of code.
Every word in a dictionary can be simplify like this "like" to be "li" and "ke". So We can use an array of 1000 strings in a shorted array (using an index array for swapping indexes) for two letters first part of a word and a second array for three letter "the", "thi". So we give a second row for that arrays where we put actual tokenized words but from second part of the word except for some numbers that means ...no other part, only a letter, and two more guards the &hffff and &hfffe. So in any string we put a guard, tokens, the second guard and an integer number as char (2 bytes).
So for finding "probaly" we have to break this in three parts, "pro","ba","ly", found the tokens, and went to "pro" second row, make the search string with the one guard plus two tokens (so 3 chars in unicode) plus second guard and find the position, or not. If not then we add the search string plus a charW(1). If we found it in position X then we add the len of the search string and we have the char where we increase the number.
We have a fault if we have a word more than 65534 times...
????????
I understand LaVolpe, DataMiser and dilettante, but your posts always confuse me. Guess they think at a higher level in Greece (been there, LOVE the country, tho).
thx, DM.... but yes, I currently have both lists 1 and 2 sorted.
....
I assume List 1 must not have been sorted at the time of your original question (two hours before your response in post #8), otherwise you wouldn't have needed that nested loop you had comparing each word to every other work in the list. All the matching words would have been adjacent to each other and you would just make one pass through the list and count the adjacent words, as DM showed.
For the example of 10,000 words, doing 10,000 (or so) compares is much faster than nested looping (10,000*10,000), so doing 100 million compares.
Last edited by passel; Dec 19th, 2014 at 05:49 PM.
If I found time I will make the code...But my problem is that I wrote my thoughts with the greek way where the object is present once and then I can write some sentences without reference to that by name, but there is a reference by the meaning of the words (For that reason Greek language is difficult to others). In Greek language you say one sentence "put the other there", and you know what is that, what is the other and where is there, because you have read the sentences before. This happen too in a conversation. Ancient greeks before Alexander the Great have no spaces in the text so to read a document you have to read from start. To separate words are simple rules, and for that rules there are multiple typed forms of phonemes. An example is the "AND" in greek writing as ΚΑΙ and is listening as two phonemes.."k" and "eh" but also there is E that have the same sound as ΑΙ.
If you like continue the reading...
So how this is helping in a text without spaces? All greek words have a theme and an ending. So when you read you read the theme and then the ending. So for each theme you now what ending can fit, so you now where the word ends. There are words with two themes and an ending, but there is no theme that is same as any ending. So Greek language is like a programming language. Prόgramma is a greek noun, that has Pro - Gram -ma, the "PRO" meaning "the thing or meaning that comes from", /"Gram" is the them of LINE so any letter is a matter of line, so this word is a noun because has an ending of a noun..."ma" (like Prάgma, the thing in english, is an noun, is ending to "ma", Ι use ά because that letter has more volume from other a and is not A as English but Ah, or the u in butter).. So programma is that thing or meaning that extract from letters. In greek language all themes have a verb also. So the verb for them "gram" is Grafo which means "to type". So you say type letters but we say Γράφω γράμματα...and the two words have the same theme...So Greek words carrying the meaning together...So writing English as thinking in Greek is wrong... (γράμμα-τα here we have two endings the last one means many, is the plural of γράμμα).
Last edited by georgekar; Dec 19th, 2014 at 06:06 PM.
This function counts words (using VbTextCompare) that are different.
I leave as exercise to alter this to get the times each word appear in the text.
Also notice that I use pointers (as offsets in arrays). Also the defined size of arrays is the maximum needed.
Also the adding of two pointers, position and size, make a list of words in an order of appearance.
Code:
Function CountWords(a$) As Long
Dim l As Long, wordbreak$
wordbreak$ = " !@#$%^&*()[]{}\/?><.,_-+=;:'" + Chr$(34) + vbCrLf
l = Len(a$)
If l = 1 Then
CountWords = -(Trim(a$) <> "")
Else
Dim pos() As Long, slen() As Long
ReDim pos(1 To l \ 2) As Long, slen(1 To l \ 2) As Long
Dim top As Long, i As Long, p As Long, k As Long
l = Len(a$)
p = 1
Do While p <= l
k = 0
Do While p + k <= l
If InStr(wordbreak$, Mid$(a$, p + k, 1)) = 0 Then Exit Do
k = k + 1
Loop
p = p + k
k = 0
Do While p + k <= l
If InStr(wordbreak$, Mid$(a$, p + k, 1)) <> 0 Then Exit Do
k = k + 1
Loop
' Debug.Print "[" & Mid$(a$, p, k) & "]"
If k = 0 Then Exit Do
For i = 1 To top
If k = slen(i) Then If StrComp(Mid$(a$, p, k), Mid$(a$, pos(i), k), vbTextCompare) = 0 Then Exit For
Next i
If i = top + 1 Then
top = i
pos(top) = p
slen(top) = k
End If
p = p + k
Loop
CountWords = top
End If
End Function
Last edited by georgekar; Dec 19th, 2014 at 08:13 PM.
Reason: drop some repeated lines...
@SamOscarBrown
Never add to a listbox in a for loop without disable it before.
When you forget that, then for each addition the listbox perform a refresh. So 10000 refreshes are a big time. A refresh wait vertical sync to send to screen. We have 50 or 60 or 70 of them...(those are the Hertz of screen refresh).
So 10000 time to loop /70 circles of refresh per second 1000/7=142.8 seconds or 2.38 minutes..
So you are right, you need minutes...
Well while it is true that the performance will be much better if you hide the list box first I doubt that it would take 2.38 minutes to add 10,000 items to the list. It may try to refresh but it does not actually do it. If you watch when adding items in a tight loop the list box will appear blank until the loop is done then they all appear at once. Now if you had a do events in there that is a whole nother story
There was a bunch of things there that was making it slow. The biggest culprit was searching through the entire list multiple times and calling that redim preserve in that loop. Combine that with the list being visible and that just adds a little more to that large amount of processing time.
Consider the list has 10,000 items, the 1st 3 match the original code would scan all 10,000 items to find a match and then it would scan them again and then again so it would go through 30,000 items 2 find the first three matches where it only needed to look at 3
Edit: Out of curiousity I tried adding 10000 items to a listbox while visible and it takes less than 1 second to complete, even with doevents in the loop it only took about 1 second so that 142.8 seconds is off by quite a lot.
Without modifying too much OP's code I got the function to be faster.
Code:
Private Sub PopList2()
Dim MyArray() As String
Dim Added As Boolean
Dim iCount As Integer
Dim i As Integer
Dim j As Integer
ReDim MyArray(List1.ListCount - 1)
For i = 0 To List1.ListCount - 1
MyArray(i) = List1.List(i)
Next
List2.Clear
List1.Visible = False
Total = List1.ListCount - 1
For i = 0 To UBound(MyArray)
For j = List1.ListCount - 1 To 0 Step -1
If LCase(List1.List(j)) = LCase(MyArray(i)) Then
If Not Added Then List2.AddItem MyArray(i)
List1.RemoveItem j
iCount = iCount + 1
If Added = False Then Added = Not Added
End If
Next
If iCount > 0 Then List2.List(List2.ListCount - 1) = List2.List(List2.ListCount - 1) & " - " & iCount
Added = False
iCount = 0
k = 0
Next
For i = 0 To UBound(MyArray)
List1.AddItem MyArray(i)
Next
List1.Visible = True
End Sub
To throw my 2cents in (along the lines of what dilettante already said) ...
GUI-elements should remain in the realm of "relative passive Visualizing"
(responsible aside from the Visualizing, only for "throwing Events back to you").
As for the task at hand - optimized "pure DataContainers" which are suitable for that, are e.g.
the VB-Collection, an ADO-Recordset, or any other Dictionary-like Object-containers which
support either a Sorting or a fast "Keybased lookup".
Below I explain this "Data-first, passive GUI-updates second" approach, using the
SortedDictionary of the vbRichClient (which is one of the fastest performing helpers
out there for stuff like this).
The following example needs (aside from a vbRichClient5-reference) 3 ListBoxes in a VB-Form
(standard-naming List1, List2, List3) ... the Sum of all Code-Snippets below will need to be pasted into it.
We start with preparation of Test-Data:
Code:
Option Explicit
Private Words() As String, D As cSortedDictionary
Private Sub Form_Load()
ScanForWords Words, 10000 'could be a FileScan or something, here we use a Random generator
Set D = New_c.SortedDictionary(TextCompare)
End Sub
Private Sub ScanForWords(Words() As String, Optional MaxWords As Long = 10000)
Dim i As Long
ReDim Words(0 To MaxWords - 1)
Rnd -1
For i = 0 To MaxWords - 1
Words(i) = "Word" & Format$(Int(Rnd * 1000) + 1, "0000")
Next i
End Sub
The above ensures the filling of the "raw Word-Data" (which could be done by a file-scan or whatever)
resulting in a "raw Words container" (the Words()-StringArray) - and we define a Helper-DataContainer,
a Sorting-Dictionary for the "counted results".
Since the GUI shall remain relative passive, we can define "non-specialized, relative dumb fill-routines" for our
3 VB-ListBoxes (which don't need to be sorting ones, since that happens on the non-GUI Data-Containers).
Code:
'just two (more or less) generically usable "dumb ListBox-Filler-Routines"
Private Sub FillListFromArray(Lst As ListBox, Arr)
Dim i As Long
Lst.Clear
For i = LBound(Arr) To UBound(Arr)
Lst.AddItem Arr(i)
Next i
End Sub
Private Sub FillListFromDictionary(Lst As ListBox, D As cSortedDictionary)
Dim i As Long
Lst.Clear
For i = 0 To D.Count - 1
Lst.AddItem D.KeyByIndex(i) & " (" & D.ItemByIndex(i) & ")"
Next i
End Sub
What we did above so far was a relative trivial task, not related to the Word-Counting at hand,
only ensuring a "structured approach" to the problem, separating GUI and Data-Containers.
So, here comes the remaining "DoAction-Code" (triggered by a Form_Click):
Code:
Private Sub Form_Click()
'let's do the real actions on the plain data-containers, ...
DoWordCountingOn Words, D
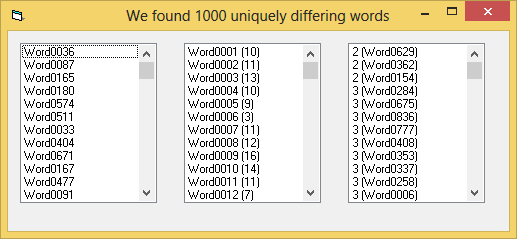
Caption = "We found " & D.Count & " uniquely differing words"
'... only later resulting in "passive" GUI-updates
FillListFromArray List1, Words
FillListFromDictionary List2, D
'and the same scheme again (data-actions first, followed by passive GUI-updates)
Set D = ReSortDictionaryByItems(D) 'data-action, resulting in a new, reordered 'D'
FillListFromDictionary List3, D 'passive GUI-update, reusing an existing generic fill-routine
End Sub
Private Sub DoWordCountingOn(Words() As String, D As cSortedDictionary)
Dim i As Long, K As String '<- we treat each incoming Word as a Key
D.RemoveAll
For i = LBound(Words) To UBound(Words)
K = Words(i): If D.Exists(K) Then D(K) = D(K) + 1 Else D.Add K, 1
Next i
End Sub
Private Function ReSortDictionaryByItems(D As cSortedDictionary) As cSortedDictionary
Dim i As Long
Set ReSortDictionaryByItems = New_c.SortedDictionary(BinaryCompare, False)
For i = 0 To D.Count - 1
ReSortDictionaryByItems.Add D.ItemByIndex(i), D.KeyByIndex(i)
Next i
End Function
As one can see, the DoWordCounting-routine is relative simple, not incorporating any
GUI-Objects - using a suitable DataContainer-Object instead, to do its specific job
(and it does that really fast).
I've introduced another routine, ReSortDictionaryByItems which follows the same
principle (doing a certain task on a non-GUI-object) - and reusing a generic and
dumb GUI-fill-routine, to update our 3rd ListBox with the resorted results (by WordCount).
Here's a ScreenShot, what the example will generate in your form:
@Datamiser
You have not to hide list, just set enable to false, do the process and change to true. About the calculation, is not true that every demand for refresh is executed in time. It depends from what os we have. Because there is a stack for gdi32 commands, and a flushing needed to perform. So from what condition the os make the final refresh? If os wait a refresh command from user, so that will be ok. But as you see from code, we don 't have a refresh command. You said that in a loop without a doevents we see a blank container. This is because the redraw routine quit before finish. This is a strategy from os programer, to gain speed? This maybe true. Because there is time to finish the redraw and while waiting, a new message reset the refresh timer, and wait again for the right time to redraw. Why didn't redraw partial? So in entire loop we would see three or four refreshes that finish. To do that, the os has to know how time have until next vertical blank. But this is not work. Os may decide to perform refresh if a mouse is moving over the listbox. So demand for redraw may occur from os too, and that, demand, has priority. So a refresh is a matter of os priorities. So user get a time penalty if controls need to redraw and that is leaving to os to decide.So if you disable the listbox by using the enable property with false value then you have no demands for redraw, no time penalty, you finish the job and then you enable again. So then because some dirty flag exist in listbox a refresh command automatic executed, so we see the refreshing list. When we use doevents we demand from os to flush any graphic job, so we change the priorities.
You can understand the os if you think what you can do if you write the os... My environment M2000 is an os in an os, with a specific language.So I make a special doevents that decide when call a doevents or a refresh, or do nothing. So I can leave it automatic or I can set the refresh counter or reset it or perform an immediate refresh. To display 10000 numbers in a scrolling window we can display with a small refresh counter value, so we see all numbers, a slow run, or with a big value we see one or two changes and the last numbers, very fast. So there is a way to setup our refresh system, as I do in M2000.
As for the task at hand - optimized "pure DataContainers" which are suitable for that, are e.g.
the VB-Collection, an ADO-Recordset, or any other Dictionary-like Object-containers which
support either a Sorting or a fast "Keybased lookup".
So, maybe, instead of placing all the words in a listbox (which I do through a load routine reading an excel spreadsheet), maybe I should simply place that word list into a DB, and do an SQL query. Do you believe that would be a much better route to take? (I am not at the computer where I have this program, so can't test 'til Monday.)
Am glad to see the many alternatives...I will try them all (well most of them that is) and see the speed comparisons. Even if I end up the DB route, I have already learned some valuable lessons about using listboxes. (And yes, both of my list boxes are sorted, but I obviously took the LONG way around in my comparison routine.) Thanks for all the advice...will post back next week.
And a small idea ..
He can take the code in #14, and there is an easy way to make it to read words from array, or excel cells. My code find words but here the words are in separate cell...so he need only the for n>1 two arrays (1 to n\2), and can place in the first array not position in string but cell position. Because he want to find how many have from each word...another array can hold..."hit" number.(hit when a word founded in list). The optimization about word length is still valuable. When equal length strings are compared we can compare partial two strings, first character....last character...from first+1 to last-1....
Well using a query would be very quick and simple.
Have you considered opening a recordset directly from the Excel file?
Could, I guess. (Done it before). I DO have to do some parsing (removing punctuation splitting by spaces, etc) (I'm pulling from different versions of the Bible from different spreadsheets, counting words in each chapter, and book). So, I guess I can do that.....but currently I read either an entire BOOK or just a CHAPTER into a textbox, parse it to a sorted listbox, and then count and place results in a second sorted listbox. CHAPTERS aren't the issue with speed, but BOOKS are. So, maybe I'll 'cheat' and load the TEXTBOX text into the DB, then do my queries from there to do the counting. (Instead of rewriting the load from Excel routine). We'll see....Monday looms. f
My words come from one column in the Spreadsheet(s), so is pretty easy to import, or even to use as a RS.
EX:
Code:
Version BookNum Book Chapter Verse Scripture
NIV 1 GENESIS 1 1 In the beginning, ......
NIV 1 GENESIS 1 2 Now earth was formless....ETC
... maybe I should simply place that word list into a DB, and do an SQL query.
Do you believe that would be a much better route to take?
That depends on, if you need the Raw-Word-Data "persisted on Disk" (in your own *.mdb copy) - or not.
If the read-out from Excel is only a "temporary thing" (when the raw Word-Data shall remain in the XL-File),
then transferring these Raw-Words into an Array first, would still be the fastest way to approach this.
In my example I filled a String-Array with these "raw words" in Form_Load (using a random generator).
But there's no problem to transfer the Raw-Words from an Excel-Sheet into an Array in your VB6-App.
Just take care, that you avoid "looping over single XL-Cells" to read out and fill such an Array.
When remoting is involved (when you open the XL-Sheet from outside XL-VBA - directly in your VB-App),
then doing the Array-Filling + Transferring in a single Remote-COM-Call is recommended.
XL supports that quite nicely - e.g. when you have your WordList in a Sheet like the following
(e.g the raw words starting in the second Column "B" downwards, and you know or calculate
the "Count of Words" in that B-Column-Range beforehand), you can do a single call like below:
At the VB-Remote-Side, WS being a Variable which holds the WorkSheet-instance...
Code:
Dim TopLeftCellAddr As String, EndOfRangeAddr As String, Words() As Variant
TopLeftCellAddr = "$B$2" '<- this is assuming, you have a HeaderCell in $B$1, Data starting from $B$2 downwards
EndOfRangeAddr = WS.Range("$B$65536").End(xlUp).Address
Words = WS.Range(TopLeftCellAddr & ":" & EndOfRangeAddr)
That's the fastest possible way, to transfer the contents of an XL-Range into an Array at the VB-Remote-Side.
The Words-Array will (despite being derived from a single Column) still be a two-dimensional one,
with LBounds at 1, so to loop over all the Words it contains, you would need to change the small
DoCounting-Routine in my example to:
Code:
Private Sub DoWordCountingOn(Words() As Variant, D As cSortedDictionary)
Dim i As Long, K As String '<- we treat each incoming Word as a Key
D.RemoveAll
For i = LBound(Words) To UBound(Words)
K = Words(i, 1): If D.Exists(K) Then D(K) = D(K) + 1 Else D.Add K, 1
Next i
End Sub
To measure the speed properly, you would have to spare out the List-Filling (or measure them
in a separate timing).
Filling VB-ListBoxes will take considerably more time than the WordCounting -
so visualizing the results in a virtual ListBox or ListView is recommended in your final solution
(in case you can't live with the ListBox-fill-times of course - depends a bit on the unique wordcounts).
Olaf
Last edited by Schmidt; Dec 20th, 2014 at 07:54 PM.
...I'm pulling from different versions of the Bible ...
...CHAPTERS aren't the issue with speed, but BOOKS are...
Ah - now there's a challenge...
So, what about scanning the whole Text-File of the King James Bible directly (bible13.txt ~5MB of data)?
This file is available for free from different sources - the version 13 textfile I've used for the
small Demo below, came from Poject Gutenberg, downloadable as a zip from this directory: http://www.gutenberg.org/files/30/old/
The parsing-routine is using SafeArrays to come up with the split-up words, working directly on
the raw FileData (leaving out all the leading comments and other stuff in the text-file automatically).
What the algorithm accomplishes performancewise (when native compiled) is the following...
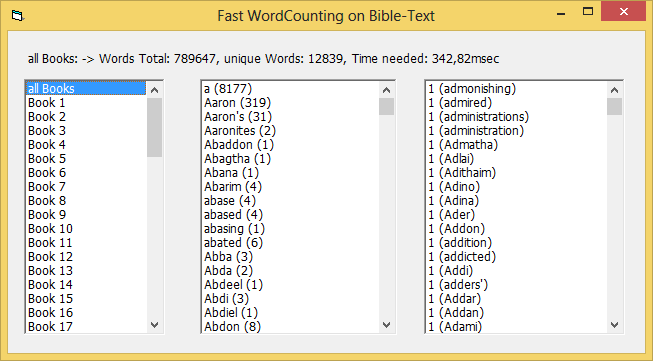
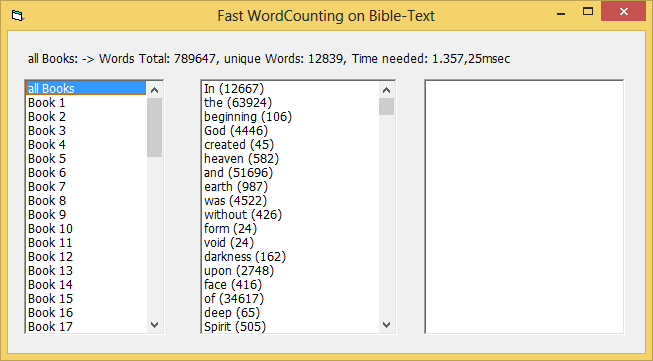
Doing a scan for all 66 books in the bible13.txt-file gives these results:
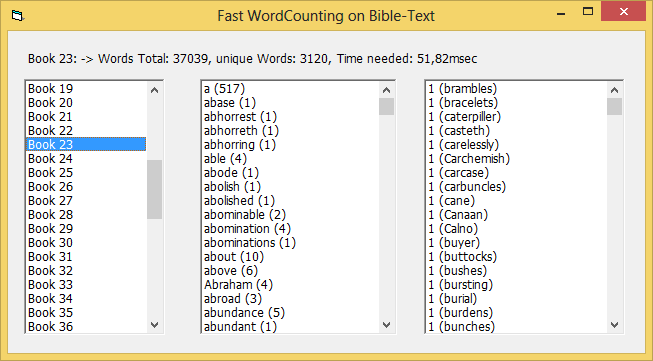
One can also specify an optional param for the scan-process, to filter for words of a given BookNr only -
below is the results for the book with the highest "unique wordcount" (book 23):
Maybe that gives a few ideas with regards to potentially avoiding all Excel-stored Data (aside from
giving an impression about the achievable timings, such things should take on raw-data of a certain size).
@George
Your current Wordsplitter is Ok for smaller sized input-data - but has still quite some room for
improvement, in case you want to do your own version against the same test-data file.
WOW! Kool, Olaf....I'll take a look. I have the ASV, NIV84, KJV and BEB all in Spreadsheet format....am importing the NIV 2011 now from a PDF. Easy to xfer all 'back to' text format, but don't wanna go through all that. I'll experiment on Monday with suggestions.
@Olaf,
I run your code. But your code is not visible, is not open source. So If I want to do it, then I have to make as closed code..but free to use, like yours.
@Olaf,
I run your code. But your code is not visible, is not open source. So If I want to do it, then I have to make as closed code..but free to use, like yours.
Well, I'd say that the VB6-code of the WordScan-routine in the example is quite visible - and in case you
don't want to use the vbRichClien5-Dictionary, then you will have to change to something else - e.g. the
MS-Scripting-Dictionary also supports StringKey-Lookups in a decent speed (but its sources are also not
available, so I don't really understand what you mean).
Well, to not leave those "out of the loop", who don't want to use the RichClients sorting dictionary...
Here's a version of the ParseWords-routine that uses the MS-Scripting.Dictionary instead:
Code:
Private Sub ParseWords(FileName$, WD As Dictionary, Optional WordCountTotal&, Optional ByVal RestrictToBookNr&)
Dim i&, j&, BookNr&, WordLen&, Idx, W$, saW As SAFEARRAY1D, FNr As Long
Dim B() As Byte, WCounts() As Long, WB() As Integer
FNr = FreeFile
Open FileName For Binary As FNr
ReDim B(LOF(FNr) - 1)
Get FNr, , B
Close FNr
W = Space$(512) 'now span a safearray over W ... for fast Wchar-access per WB()
saW.cDims = 1
saW.cbElements = 2
saW.lLbound1D = -2
saW.cElements1D = Len(W) + 2
saW.pvData = StrPtr(W) - 4
BindArray WB, VarPtr(saW) 'now we bind WB() -> W
WordCountTotal = 0 'reset the WordTotal-Counter
WB(-2) = 0 'set the initial StrLenB to zero
Set WD = New Scripting.Dictionary
WD.CompareMode = TextCompare
ReDim WCounts(8192)
For i = 1 To UBound(B)
If B(i) = 66 And B(i - 1) = 10 Then 'check potential new "Book-Headers"
j = i: Do Until B(i) = 10: i = i + 1: Loop '...and skip to the next linefeed
If i - j <= 31 Then BookNr = BookNr + 1
End If
Select Case B(i)
Case 39, 65 To 90, 97 To 122 'add the char into our current Single-Word Array
WB(WordLen) = B(i): WordLen = WordLen + 1
Case Else 'it's whitespace
If WordLen > 0 Then 'WordLen is only > 0 on the first (new) WhiteSpace-Char, follwing a word,
If BookNr > 0 And (RestrictToBookNr = 0 Or RestrictToBookNr = BookNr) Then
WB(-2) = WordLen + WordLen 'so now we adjust the LenB-Field of the "array-mapped BString"
WB(WordLen) = 0 'and set a terminating zero-WChar
Idx = WD.Item(W) 'Ok, now we can use W, to perform an exists-check
If IsEmpty(Idx) Then 'Word doesn't exist yet in dictionary
Idx = WD.Count 'so we assign the Idx-Variable to the next free index-slot
WD(W) = Idx 'and add the new Word into our Dictionary
If Idx > UBound(WCounts) Then ReDim Preserve WCounts(2 * Idx)
End If
WCounts(Idx) = WCounts(Idx) + 1
WordCountTotal = WordCountTotal + 1
If i + 15 < UBound(B) Then If B(i + 15) = 42 Then Exit For 'we reached the end of Book 66 and exit here
End If
WordLen = 0
End If
End Select
Next i
saW.pvData = 0: saW.cElements1D = 0
ReleaseArray WB 'release the "WB()-> W" safearray-binding
Dim Keys(): Keys = WD.Keys
Dim Items(): Items = WD.Items
For i = 0 To WD.Count - 1: WD(Keys(i)) = WCounts(Items(i)): Next
End Sub
The Fill-Routine for the ListBox could be made Scripting.Dictionary compatible this way:
Code:
Private Sub FillListFromDictionary(Lst As ListBox, WD As Dictionary)
Dim i As Long, Keys(), Items()
Lst.Visible = False: Lst.Clear
Keys = WD.Keys
Items = WD.Items
For i = 0 To WD.Count - 1
Lst.AddItem Keys(i) & " (" & Items(i) & ")"
Next i
Lst.Visible = True
End Sub
Well, all that brings a performance which is about factor 4 less than before -
and is also not yet accomplishing a sorted delivery of the unique words -
but this might still be "Ok" for many purposes.
Here's what the version with the Scripting-Dictionary will produce (with the small changes as shown above):
In a form we place a rtb. No distinguish books...nor headers.
Countwords make no sort. I leave the order of appearance. We can feed a listbox with sort capability. It isn't the best one, but uses no external class, such as MS-Scripting.Dictionary.
I also include the reading routine for text files.
GetWord routine optimizes the expansion of string.
Getcount uses no string expression. Only pointers. This is fast. But because we can use binary search isn't as fast as I wish. Next time I put a sort routine..and I move only pointers..
Code:
dim a$, jj as long, kk as long
a$ = ReadUnicodeOrANSI(App.Path & "\Bible13.txt")
jj = CountWords(a$)
Caption = jj
Text1 = ""
c$ = Space$(200)
kk = 1
For i = 1 To jj
GetWord i, a$, c$, kk
Next i
Text1 = Trim(c$)
This is for a module
Code:
Declare Function GetShortPathName Lib "kernel32" Alias _
"GetShortPathNameW" (ByVal lpszLongPath As Long, _
ByVal lpszShortPath As Long, ByVal cchBuffer As Long) As Long
Private Declare Function WideCharToMultiByte Lib "kernel32" (ByVal codepage As Long, ByVal dwFlags As Long, ByVal lpWideCharStr As Long, ByVal cchWideChar As Long, ByVal lpMultiByteStr As Long, ByVal cchMultiByte As Long, ByVal lpDefaultChar As Long, ByVal lpUsedDefaultChar As Long) As Long
Declare Function MultiByteToWideChar& Lib "kernel32" (ByVal codepage&, ByVal dwFlags&, MultiBytes As Any, ByVal cBytes&, ByVal pWideChars&, ByVal cWideChars&)
Declare Function CompareString Lib "kernel32" Alias "CompareStringW" (ByVal Locale As Long, ByVal dwCmpFlags As Long, ByVal lpString1 As Long, ByVal cchCount1 As Long, ByVal lpString2 As Long, ByVal cchCount2 As Long) As Long
Public Declare Function GetLocaleInfoW Lib "kernel32" (ByVal Locale As Long, ByVal LCType As Long, ByVal lpLCData As Long, ByVal cchData As Long) As Long
Private Declare Function GetKeyboardLayout& Lib "user32" (ByVal dwLayout&) ' not NT?
Private Const DWL_ANYTHREAD& = 0
Const LOCALE_ILANGUAGE = 1
Public curLCID As Long
Public p3 As Long
Public pos() As Long, slen() As Long, hit() As Long
Public Sub DropLeft(ByVal uStr As String, fromStr As String)
Dim i As Long
i = InStr(fromStr, uStr)
If i > 0 Then
fromStr = Mid$(fromStr, i + Len(uStr))
Else
fromStr = ""
End If
End Sub
Sub GetWord(i As Long, a$, b$, cur)
Dim k$
k$ = Mid$(a$, (pos(i) - p3) / 2 + 1, slen(i)) & " (" & CStr(hit(i) + 1) & ")" + vbCrLf
If Len(b$) < cur + Len(k$) Then b$ = b$ + Space$(Len(b$))
Mid$(b$, cur, Len(k$)) = k$
cur = cur + Len(k$)
End Sub
Function CountWords(a$) As Long
Dim l As Long, wordbreak$, ml As Long
Const NORM_IGNORECASE = &H1
wordbreak$ = " !@#$%^&*()[]{}\/?><.,_-+=;:'1234567890~`" + Chr$(34) + vbCrLf
ml = (Len(wordbreak$)) * 2
l = Len(a$)
If l = 1 Then
CountWords = -(Trim(a$) <> "")
Else
ReDim pos(1 To l \ 2 + 1) As Long, slen(1 To l \ 2 + 1) As Long, hit(1 To l \ 2 + 1) As Long
Dim top As Long, i As Long, p As Long, k As Long, pa As Long, m As Long, pm As Long
p = 1
Dim P2 As Long
P2 = StrPtr(a$)
p3 = P2
p3check = P2
pm = StrPtr(wordbreak)
Dim ok As Boolean
l = P2 + 2 * l
Do While P2 < l
k = 0
Do While P2 + k < l
ok = False
For m = pm To pm + ml Step 2
If CompareString(0, 0, m, 1, P2 + k, 1) = 2 Then ok = True: Exit For
Next m
If Not ok Then Exit Do
k = k + 2
Loop
P2 = P2 + k
k = 2
Do While P2 + k < l
ok = False
For m = pm To pm + ml Step 2
If CompareString(0, 0, m, 1, P2 + k, 1) = 2 Then ok = True: Exit For
Next m
If ok Then Exit Do
k = k + 2
Loop
If k = 0 Or P2 >= l Then Exit Do
k = k \ 2
For i = 1 To top
If k = slen(i) Then
If CompareString(0, NORM_IGNORECASE, P2, k, pos(i), k) = 2 Then
hit(i) = hit(i) + 1
Exit For
End If
End If
Next i
If i = top + 1 Then
top = i
pos(top) = P2
slen(top) = k
End If
P2 = P2 + 2 * k
Loop
CountWords = top
End If
End Function
Public Function GetDosPath(LongPath As String) As String
Dim s As String
Dim i As Long
Dim PathLength As Long
i = Len(LongPath) * 2 + 2
s = String(1024, 0)
PathLength = GetShortPathName(StrPtr(LongPath), StrPtr(s), i)
GetDosPath = Left$(s, PathLength)
End Function
Function ReadUnicodeOrANSI(Filename As String, Optional ByVal EnsureWinLFs As Boolean, Optional feedback As Long) As String
Dim i&, FNr&, BLen&, WChars&, BOM As Integer, BTmp As Byte, b() As Byte
' code from Schmidt, member of vbforums
If Filename = "" Then Exit Function
On Error GoTo ErrHandler
BLen = FileLen(GetDosPath(Filename))
If BLen = 0 Then Exit Function
FNr = FreeFile
Open GetDosPath(Filename) For Binary Access Read As FNr
Get FNr, , BOM
Select Case BOM
Case &HFEFF, &HFFFE 'one of the two possible 16 Bit BOMs
If BLen >= 3 Then
ReDim b(0 To BLen - 3): Get FNr, 3, b 'read the Bytes
feedback = 0
If BOM = &HFFFE Then 'big endian, so lets swap the byte-pairs
feedback = 1
For i = 0 To UBound(b) Step 2
BTmp = b(i): b(i) = b(i + 1): b(i + 1) = BTmp
Next
End If
ReadUnicodeOrANSI = b
End If
Case &HBBEF 'the start of a potential UTF8-BOM
Get FNr, , BTmp
If BTmp = &HBF Then 'it's indeed the UTF8-BOM
feedback = 2
If BLen >= 4 Then
ReDim b(0 To BLen - 4): Get FNr, 4, b 'read the Bytes
WChars = MultiByteToWideChar(65001, 0, b(0), BLen - 3, 0, 0)
ReadUnicodeOrANSI = Space$(WChars)
MultiByteToWideChar 65001, 0, b(0), BLen - 3, StrPtr(ReadUnicodeOrANSI), WChars
End If
Else 'not an UTF8-BOM, so read the whole Text as ANSI
feedback = 3
ReadUnicodeOrANSI = Space$(BLen)
Get FNr, 1, ReadUnicodeOrANSI
End If
Case Else 'no BOM was detected, so read the whole Text as ANSI
feedback = 3
ReadUnicodeOrANSI = Space$(BLen)
Get FNr, 1, ReadUnicodeOrANSI
End Select
If InStr(ReadUnicodeOrANSI, vbCrLf) = 0 Then
If InStr(ReadUnicodeOrANSI, vbLf) Then
feedback = feedback + 10
If EnsureWinLFs Then ReadUnicodeOrANSI = Replace(ReadUnicodeOrANSI, vbLf, vbCrLf)
ElseIf InStr(ReadUnicodeOrANSI, vbCr) Then
feedback = feedback + 20
If EnsureWinLFs Then ReadUnicodeOrANSI = Replace(ReadUnicodeOrANSI, vbCr, vbCrLf)
End If
End If
ErrHandler:
If FNr Then Close FNr
If Err Then Err.Raise Err.Number, Err.Source & ".ReadUnicodeOrANSI", Err.Description
End Function
Public Function GetLCIDFromKeyboard() As Long
Dim Buffer As String, Ret&, r&
Buffer = String$(514, 0)
r = GetKeyboardLayout(DWL_ANYTHREAD) And &HFFFF
r = Val("&H" & Right(Hex(r), 4))
Ret = GetLocaleInfoW(r, LOCALE_ILANGUAGE, StrPtr(Buffer), Len(Buffer))
GetLCIDFromKeyboard = CLng(Val("&h" + Left$(Buffer, Ret - 1)))
End Function
Last edited by georgekar; Dec 21st, 2014 at 02:31 PM.
Reason: Update GETWORD and WordBreak$ const
Sam,
Re. ListBoxes
1. We touched upon related stuff back in http://www.vbforums.com/showthread.p...83#post4654083
2. If you are in a real hurry and you have a longish list it can be faster to sort the list in code and then add it to an unsorted ListBox.
Sam,
Re. ListBoxes
1. We touched upon related stuff back in http://www.vbforums.com/showthread.p...83#post4654083
2. If you are in a real hurry and you have a longish list it can be faster to sort the list in code and then add it to an unsorted ListBox.
That we did, 8 months ago! (unfortunately for old men, memories ain't like they used to be). I THINK what I'll end up doing is not using ANY list boxes, but end up loading the excel files into a db (I am so much more used to queries from that than using Excel data in a recordset.---and recall my comment about old men. And, instead of doing all this on the fly, I can keep it resident (without referring back to Excel) and only return my already parsed, counted, sourced data. (IOW, will have a table that is derived from others and contains the counts already. So, no matter how long it takes the FIRST time, when I run the program later on, it will be instantaneous. (Of course, at that point, I may use a list box to display it). Lots of good communication on this subject....hope to learn a whole lot more next week as I experiment with
these great suggestions. Thanks, all....
What is the Definition of SAFEARRAY1D in your last post.
It's in the small 2.9KB-Zip (at the bottom of my post #26).
What I posted in #30 was thought as replacements for existing routines in the Basecode which
came in that Zip. (Its content is just a *.vbp and a *.frm, with already placed ListBoxes, already
set ProjectReferences and Compiler-Settings - just add the additional reference to the MS-
Scripting-Runtime - and comment out the 2 or 3 other, still cSortedDictionary related Code-lines.
GK..I have NO idea what you just posted. Are you insinuating that I can simply copy your code (which I don't generally do) and I will be able to import an excel spreadsheet, find all the words in the sixth column, and I will magically find the number of times that each word is found,, rapidly? I didn't think so....PLEASE keep you your posts directly related to the problem. ευχαριστίες.
@SamOscarBrown,
Its time to read code...
So if you read that is a quicksort for my example
But I found a better way to sort words. Without Quick sort. I found a way to sort the list of word while I do a binary search. If I didn't find the word then the binary search gives me the position to put the pointers..so i copy the memory to leave a a place to put my pointes. So this routine is 2 times faster from my previous one, and do the sorting also. I try the binary search with quick sort and it is 9 times more slow...
I put it on the code of Olaf, but works only for all bibles.
I didn't alter the time measure system, so we see all time to display also some 13000 words
So No I haven't make the word counter for excel cells. My routine finds words in a string. So can be used everywhere that you can put a document in a string.
? strcomp("Aaronites","Aaron's",vbtextCompare)
Aaronites is before Aaron's
but in Olaf sort is after???
but he use this " Set WD = New_c.SortedDictionary(TextCompare)"
so what is the right??
Last edited by georgekar; Dec 21st, 2014 at 06:35 PM.
I found another part that is not sorted by vbtextcompare...in olaf routine
This is from my routine (i can cut because is written in an RTB. Olaf's is in a Listbox...)
George, your current solution is (native compiled, 24sec for the whole bible) still about factor 72! slower than
the one with the RC5.SortedDictionary... and about Factor 18 slower than the one with the MS-Scripting.Dictionary.
So, my suggestion would be, to adopt the fast Word-Splitting-routine I wrote - try to understand what
the SafeArray-Type is doing in that context - perhaps followed by writing your own, fast implementation
of a List-class in either Collection- or Dictionary-Style (in case you find the usability of those already
tested and precompiled Binaries insufficient).






 Reply With Quote
Reply With Quote