Just to throw something new (for VB6) into the ring of competing Sort-Algos...
I've just finished porting (from Java-SourceCode) the relative new (Sep. 2009) Dual-Pivot-Algorithm, invented by
Vladimir Yaroslavskiy, who has tuned good old QuickSort significantly, leaving over next to zero disadvantages.
The source for this new Algo is contained in the attached Demo-Zip.
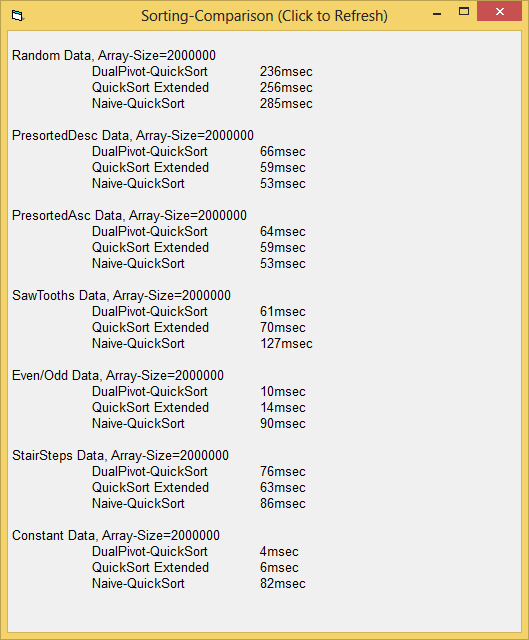
Here's a Screenshot, which shows its performance with different kinds of Input-Data:
With normal (random) Data it shows no disadvantages to a Standard-QuickSort -
but offers huge improvements over "naive Quicksorts" when fed with "inconvenient data".
As a side-note:
HeapSort is outperformed in all tests quite significantly by the DualPivot-Algo...
HeapSort is also beaten by the naive QuickSort in all tests, except the one with constant Data.
Olaf
Last edited by Schmidt; Nov 16th, 2014 at 01:40 AM.
I make the Native-Extended Quick sort...With better performance from in some situation from native quicksort.
Code:
Public Sub NaiveQuickSortExtended(Arr() As Long, ByVal LB As Long, ByVal UB As Long)
Dim M1 As Long, M2 As Long
Dim Piv As Long, Tmp As Long '<- adjust types here, when switching to something different than Long
If UB - LB = 1 Then
M1 = LB: GoTo there4
Else
Tmp = (LB + UB) \ 2
If Arr(Tmp) = Arr(LB) Then
M2 = UB
Tmp = LB
Do
Tmp = Tmp + 1
If Tmp > M2 Then GoTo there3
Loop Until Arr(Tmp) <> Arr(LB)
End If
End If
M1 = LB
M2 = UB
Piv = Arr(Tmp) 'create the Pivot-Element
Do
Do While (Arr(M1) < Piv): M1 = M1 + 1: Loop
Do While (Arr(M2) > Piv): M2 = M2 - 1: Loop
If M1 <= M2 Then
Tmp = Arr(M1): Arr(M1) = Arr(M2): Arr(M2) = Tmp 'swap
M1 = M1 + 1
M2 = M2 - 1
End If
Loop Until M1 > M2
If LB < M2 Then NaiveQuickSortExtended Arr, LB, M2
If M1 < UB Then NaiveQuickSortExtended Arr, M1, UB
Exit Sub
there3:
For M1 = LB + 1 To UB - 1
If Arr(M1) <> Arr(LB) Then Exit For
Next M1
If M1 < UB - 1 Then
NaiveQuickSortExtended Arr(), M1, UB
ElseIf M1 < UB Then
there4:
If Arr(M1) > Arr(UB) Then Tmp = Arr(M1): Arr(M1) = Arr(UB): Arr(UB) = Tmp
Else
If Arr(UB) < Arr(LB) Then Tmp = Arr(LB): Arr(LB) = Arr(UB): Arr(UB) = Tmp
End If
End Sub
This is from Xp in Virtual Box..with no optimizations except "for fast code"..
Last edited by georgekar; Nov 16th, 2014 at 08:43 PM.
I change the use of tmp so If we want we can change it to string without need for another var.
Code:
Public Sub NaiveQuickSortExtended(Arr() As Long, ByVal LB As Long, ByVal UB As Long)
Dim M1 As Long, M2 As Long
Dim Piv As Long, Tmp As Long '<- adjust types here, when switching to something different than Long
If UB - LB = 1 Then
M1 = LB: GoTo there4
Else
M1 = (LB + UB) \ 2
If Arr(M1) = Arr(LB) Then
M2 = UB
M1 = LB
Do
M1 = M1 + 1
If M1 > M2 Then GoTo there3
Loop Until Arr(M1) <> Arr(LB)
End If
End If
Piv = Arr(M1)
M1 = LB
M2 = UB
'create the Pivot-Element
Do
Do While (Arr(M1) < Piv): M1 = M1 + 1: Loop
Do While (Arr(M2) > Piv): M2 = M2 - 1: Loop
If M1 <= M2 Then
Tmp = Arr(M1): Arr(M1) = Arr(M2): Arr(M2) = Tmp 'swap
M1 = M1 + 1
M2 = M2 - 1
End If
Loop Until M1 > M2
If LB < M2 Then NaiveQuickSortExtended Arr, LB, M2
If M1 < UB Then NaiveQuickSortExtended Arr, M1, UB
Exit Sub
there3:
For M1 = LB + 1 To UB - 1
If Arr(M1) <> Arr(LB) Then Exit For
Next M1
If M1 < UB - 1 Then
NaiveQuickSortExtended Arr(), M1, UB
ElseIf M1 < UB Then
there4:
If Arr(M1) > Arr(UB) Then Tmp = Arr(M1): Arr(M1) = Arr(UB): Arr(UB) = Tmp
Else
If Arr(UB) < Arr(LB) Then Tmp = Arr(LB): Arr(LB) = Arr(UB): Arr(UB) = Tmp
End If
End Sub
I change the use of tmp so If we want we can change it to string without need for another var.
Code:
Public Sub NaiveQuickSortExtended(Arr() As Long, ByVal LB As Long, ByVal UB As Long)
Dim M1 As Long, M2 As Long
Dim Piv As Long, Tmp As Long '<- adjust types here, when switching to something different than Long
If UB - LB = 1 Then
M1 = LB: GoTo there4
Else
M1 = (LB + UB) \ 2
If Arr(M1) = Arr(LB) Then
M2 = UB
M1 = LB
Do
M1 = M1 + 1
If M1 > M2 Then GoTo there3
Loop Until Arr(M1) <> Arr(LB)
End If
End If
Piv = Arr(M1)
M1 = LB
M2 = UB
'create the Pivot-Element
Do
Do While (Arr(M1) < Piv): M1 = M1 + 1: Loop
Do While (Arr(M2) > Piv): M2 = M2 - 1: Loop
If M1 <= M2 Then
Tmp = Arr(M1): Arr(M1) = Arr(M2): Arr(M2) = Tmp 'swap
M1 = M1 + 1
M2 = M2 - 1
End If
Loop Until M1 > M2
If LB < M2 Then NaiveQuickSortExtended Arr, LB, M2
If M1 < UB Then NaiveQuickSortExtended Arr, M1, UB
Exit Sub
there3:
For M1 = LB + 1 To UB - 1
If Arr(M1) <> Arr(LB) Then Exit For
Next M1
If M1 < UB - 1 Then
NaiveQuickSortExtended Arr(), M1, UB
ElseIf M1 < UB Then
there4:
If Arr(M1) > Arr(UB) Then Tmp = Arr(M1): Arr(M1) = Arr(UB): Arr(UB) = Tmp
Else
If Arr(UB) < Arr(LB) Then Tmp = Arr(LB): Arr(LB) = Arr(UB): Arr(UB) = Tmp
End If
End Sub
where is the sort direction? Please make sorting routine be ready to use for beginner.
Better, more optimizations...and I switch on the compiler optimizations...so now I get better numbers.
@Jonney
Take the Schmidt zip file and paste the NaiveQuickSortExtended in the bas file with the NaiveQuickSort sub. You can put this code the form among the other routines.
Code:
FillArray Arr, FillMode: DoEvents
Timing True
NaiveQuickSortExtended Arr, 0, UBound(Arr)
Print , "Naive-QuickSort Extended", Timing
If VerifyResults Then For i = 0 To UBound(Arr): Debug.Assert Arr(i) = ArrVerify(i): Next
Code:
Public Sub NaiveQuickSortExtended(Arr() As Long, ByVal LB As Long, ByVal UB As Long)
Dim M1 As Long, M2 As Long
Dim Piv As Long, Tmp As Long '<- adjust types here, when switching to something different than Long
If UB - LB = 1 Then
M1 = LB: GoTo there4
Else
M1 = (LB + UB) \ 2
If Arr(M1) = Arr(LB) Then
M2 = UB
M1 = LB
Do
M1 = M1 + 1
If M1 > M2 Then GoTo there3
Loop Until Arr(M1) <> Arr(LB)
Piv = Arr(M1)
If M1 > LB Then
If Arr(LB) > Piv Then Arr(M1) = Arr(LB): Arr(LB) = Piv: Piv = Arr(M1)
End If
Else
Piv = Arr(M1)
M1 = LB
Do While (Arr(M1) < Piv): M1 = M1 + 1: Loop
End If
End If
M2 = UB
Do
Do While (Arr(M2) > Piv): M2 = M2 - 1: Loop
If M1 <= M2 Then
Tmp = Arr(M1): Arr(M1) = Arr(M2): Arr(M2) = Tmp 'swap
M1 = M1 + 1
M2 = M2 - 1
End If
If M1 > M2 Then Exit Do
Do While (Arr(M1) < Piv): M1 = M1 + 1: Loop
Loop
If LB < M2 Then NaiveQuickSortExtended Arr, LB, M2
If M1 < UB Then NaiveQuickSortExtended Arr, M1, UB
Exit Sub
there3:
For M1 = LB + 1 To UB - 1
If Arr(M1) <> Arr(LB) Then Exit For
Next M1
If M1 < UB - 1 Then
NaiveQuickSortExtended Arr(), M1, UB
ElseIf M1 < UB Then
there4:
If Arr(M1) > Arr(UB) Then Tmp = Arr(M1): Arr(M1) = Arr(UB): Arr(UB) = Tmp
Else
If Arr(UB) < Arr(LB) Then Tmp = Arr(LB): Arr(LB) = Arr(UB): Arr(UB) = Tmp
End If
End Sub
This is the final code. I remove some old parts that isn't used any more and also I remove goto...It is faster than Dual-Pivot except in one test, Even Odd data, but is close to Dual-Pivot and not to naive-Quick Sort.
The optimization now is clear in a position before the naive quick sort. In many cases is faster than quick sort.
Code:
Public Sub NaiveQuickSortExtended(Arr() As Long, ByVal LB As Long, ByVal UB As Long)
Dim M1 As Long, M2 As Long
Dim Piv As Long, Tmp As Long '<- adjust types here, when switching to something different than Long
If UB - LB = 1 Then
M1 = LB
If Arr(M1) > Arr(UB) Then Tmp = Arr(M1): Arr(M1) = Arr(UB): Arr(UB) = Tmp
Exit Sub
Else
M1 = (LB + UB) \ 2
If Arr(M1) = Arr(LB) Then
M2 = UB - 1
M1 = LB
Do
M1 = M1 + 1
If M1 > M2 Then
If Arr(UB) < Arr(LB) Then Tmp = Arr(LB): Arr(LB) = Arr(UB): Arr(UB) = Tmp
Exit Sub
End If
Loop Until Arr(M1) <> Arr(LB)
Piv = Arr(M1)
If M1 > LB Then If Arr(LB) > Piv Then Arr(M1) = Arr(LB): Arr(LB) = Piv: Piv = Arr(M1)
Else
Piv = Arr(M1)
M1 = LB
Do While (Arr(M1) < Piv): M1 = M1 + 1: Loop
End If
End If
M2 = UB
Do
Do While (Arr(M2) > Piv): M2 = M2 - 1: Loop
If M1 <= M2 Then
Tmp = Arr(M1): Arr(M1) = Arr(M2): Arr(M2) = Tmp 'swap
M1 = M1 + 1
M2 = M2 - 1
End If
If M1 > M2 Then Exit Do
Do While (Arr(M1) < Piv): M1 = M1 + 1: Loop
Loop
If LB < M2 Then NaiveQuickSortExtended Arr, LB, M2
If M1 < UB Then NaiveQuickSortExtended Arr, M1, UB
End Sub
This is the final code. I remove some old parts that isn't used any more and also I remove goto...It is faster than Dual-Pivot except in one test, Even Odd data, but is close to Dual-Pivot and not to naive-Quick Sort.
The optimization now is clear in a position before the naive quick sort. In many cases is faster than quick sort.
Thanks George - will take a better look at it the next days.
If you have unique keys to sort then quick sort without extensions is very fast. For multiple part key, if you have the first part unique then the others have no meaning, so you need only the last part to be unique....So we say that before choosing the right sort algorithm you have to realise how your data spread in your multi dimension array, defining a validaton procedure.
Make the compare function from column a to b. If you find not equal before b do not go further and exit with result. If you find all equal including items in b column...that means you hit an error. The data are not acceptable to store. So your routine has to return two values, one for greater or lower, and one flag that say...not valid for unique keys.
So with unique keys you have no situations as for even odd values (they aren't unique keys in Olaf example), or constant value. For safety I suggest the extented version...but you loose speed (you gain if there are equal keys..by a bad handle from other spot). Also with extended version you can check the key conflicts and get measures, like a spare part key that is always null, hidden, and before final to assign a value using the spare part key in item in LB as a counter.So the extended version can fix the keys to be unique at the sorting stage, but the user never see the hidden part. He get the sorting quick...and that is what we need...
Last edited by georgekar; Nov 19th, 2014 at 05:52 AM.
For descending - especially with multi keyed sorts - subtract the "key" from 9999999999's if it's a number, or for even cleaner results subtract each BYTE from "255" and sort that KEY. That does a descending sort with no changes to any other aspects of the sort or how you loop the data.
For duplicate keys I always retain a "sequencer" column in each row. That value is used to break ties, and by doing so you have a STABLE sort for when a user is clicking and re-clicking different grid columns, for instance.
*** Read the sticky in the DB forum about how to get your question answered quickly!! ***
Please remember to rate posts! Rate any post you find helpful - even in old threads! Use the link to the left - "Rate this Post".
For descending - especially with multi keyed sorts - subtract the "key" from 9999999999's if it's a number, or for even cleaner results subtract each BYTE from "255" and sort that KEY. That does a descending sort with no changes to any other aspects of the sort or how you loop the data.
For duplicate keys I always retain a "sequencer" column in each row. That value is used to break ties, and by doing so you have a STABLE sort for when a user is clicking and re-clicking different grid columns, for instance.
This is a very nice and interesting bit of code, Olaf - thank you for sharing.
One question. I notice that the presorted data sets (and occasionally the random data set) perform quite poorly relative to a naive QuickSort. This isn't the case in either the Java SDK implementation, or some of the C implementations I've looked at. Is there a way to reduce the Dual Pivot penalty for these data sets?
Sample timings below, tested on a Win 7 box, older Core i5 processor (Clarkdale era), compiled EXE:
These timing results could be due to branch prediction failure in older processors like this, which could make the issue hard to fix, but I thought I'd ask anyway.
Can you test the NaiveQuickSortExtended from post #7
Definitely! Here are the updated results, with NaiveQuickSortExtended added to the mix. (I called it "Extended-QuickSort", so tabstops would align in the chart.)
I am happy. My last inspiration was to throw the pivot choice when a duplicate item founded in the start and then I do a search in the first items for a non duplicate, and if i found then i know that some items are the same and I do a swap if the not same item is less than the multiple item. So maybe all items are the same one, so i do n comparisons and not one swap and at the end i do an exit sub. So for constant data that is the most speedy approach. We see 12msec in Jonney's data. For Even/Odd data I think that I was lucky. Every time founded that the middle and first are equal, and the search stop to the second item, so a swap happen.. and the pivot now is the maximum "even" in the second position, so they start to swap....until all done..so in the next step we have nothing to do except to work as in constant data. My thought was for that two tests. But I see that has good times in every test...
This is a very nice and interesting bit of code, Olaf - thank you for sharing.
One question. I notice that the presorted data sets (and occasionally the random data set) perform quite poorly relative to a naive QuickSort. This isn't the case in either the Java SDK implementation, or some of the C implementations I've looked at. Is there a way to reduce the Dual Pivot penalty for these data sets?
The Dual-Pivot-Algo has an interesting property - in that it needs even less comparisons than
the (already very good in that regard) Standard-Quicksort.
The following picture might underline that (in the Zip below I've included an appropriate Folder
with the CC-Counter extended versions you see in the ScreenShot).
(one can ignore the timings in this Shot - it's the Count of needed comparisons which is interesting there...)
The Dual-Pivot achieves that at the cost of the Swaps (which it needs to perform in a greater
amount - at least in the random case - than Standard-Quicksorts).
And that's the main-reason (aside from a bit of tuning which was still missing in my first "straight port"), why the
*VB-implemented* Standard-Quicksorts perform better in some cases (the naive one as well as Georges extended one).
VB has a little disadvantage with its SafeArrays there, compared to "straight accessible" ones in C- or Java-Hotspot-
compiled implementations. So that's the main-reason why in VB the Dual-Pivot doesn't outperform normal Quicksorts
as it does in other languages - the less comparisons don't outweigh its larger swap-counts due to VBs lesser
Swap-Performance.
Nevertheless I've tuned the DualPivot a bit now, and achieve (on Long-Arrays) these Results:
Algorithms which need less comparisons are often preferred - simply because they can be used then (as e.g. the
qsort-function in the C-Runtime-Lib) for delegation to an (a bit more expensive) userdefined-compare-callback -
and also because StringSorts (which are also expensive in their compares) profit very well from such an algo -
even when the needed Swap-Counts are a bit higher... At least C (not sure about Java) allows direct String-Pointer-
Swapping, so the costs of these swaps remain comparable to the swap-performance of Long-Arrays, whilst
the time which is needed for the string-comparisons profits very much from the less compares of the DualPivot.
In VB we can test and simulate this by introducing an additional Index-Array - performing an indirect sort.
I've prepared a third Folder in the Zip, in which I've adapted Georges latest version and the DualPivot
to indirect String-Sorting.
The performance (which after my tuning was roughly on par with Georges Extended Quicksort in case of Longs)
is now clearly better when Strings need to be sorted:
Here's the Zip with the updated Version of the DualPivot, containing 3 Folders:
.\DualPivotQuickSortCountComparisons
.\DualPivotQuickSortLong
.\DualPivotQuickSortString
Edit, now also containing the Folder (and some slight changes for unique Index-Swaps):
.\DualPivotQuickSortApplied
to address the problem mentioned in the posting below (#21)
@Olaf,
I have my reply here. I change also the rules, from a simple indexing array to go further, and I really want to see how fast this Double Pivot Quick Sort (DPQS) is. So I take my trusty myDoc class, that work as a document with paragraphs, dynamically arranged by using a doubly linked list. The task was hard because DPQS have some series of swap, for 3 and 4 items. So to maintain the doubly linked list it was necessary for that situations only to add another stage of sorting, the sorting of the list of that item that we have to unlink and then link to new positions in the document. I use the shell sort with expansion of a "position" array.
Here are the results. For random strings (or paragraphs for document) we see that the simpler Quick Sort Extended are faster than Double Pivot Quick Sort.
(i do a lot of changes to your program..sorry)
Last edited by georgekar; Nov 23rd, 2014 at 03:02 PM.
I have my reply here. I change also the rules, from a simple indexing array to go further, and I really want to see how fast this Double Pivot Quick Sort (DPQS) is.
What was said (in that it needs less Comparisons, which is nice when sorting strings) remains unchanged -
so when you apply this algo to a specific task *correctly*, then you will see appropriate results.
Here's my take at it (applying the algo somewhat more efficient to your "Doc-Sorting-problem").
At this occasion I did the same thing also with your extended Quicksort, so that both algorithms
now sort your Doc about 6 times as fast.
After a slight change (to ensure unique index-swaps) in the indirect Sorting, you now see these results:
I've re-uploaded the Comparison-Zip with the indirect String-Sorting under the same link as in Post #20,
but below it is again (now including also your TestFolder under \DualPivotQuickSortApplied): DualPivotQuickSortComparisons.zip
And BTW George - your Doc-Class (Double-Linked-List) implementation is not really "enjoyable".
It's an overcomplicated monster if you ask me, which could be reduced (using a decent Collection-
Class) to about a fifth of its current code-volume - at least.
Olaf
Last edited by Schmidt; Nov 23rd, 2014 at 11:11 PM.
@Olaf,
I see your changes; You do a copy of data from linked list to a string array and the over time is due to link fixation on the last stage. We have a splendid speedy algo, but with one bad thing (not bad always, in this case is), we copy the data. If we use string compare in place, by using pointers, then we have no string transfer, and the comparison ends before the end of the reading (if routine found a non equal char early, so never copied entirely all the string data). This can be applied in any sort routine which deal with strings. You can see that I use a KeyStart variable to isolate first chars. So we have Mid$ that expect string expression, and copy the string to a temporary string and return the string to be compare. So with the copy that you did, in newest your version, in an array before sort starts, you gain time by using this manipulation once for each array item. Using the api to compare strings means that we can provide the right offset ...if each string is long enough. So we need a small code to decide if we can compare (perhaps we have an empty string or lower form KeyStart) and then we provide the right offset (keystart*2). An off topic here: The idea of Keystart is to split a string in two parts, the one part is a record with fix width fields, and the other part is a key with variable length. This key can be anything form simple chars to a strange output of a hash code. Also a variable key can serve as a path, so we can use the list as a tree list.
I see that you remove the DPQS from myDoc class, and also the needed functions to operate the list. This changed routine (and missing from your last example, but is in mine in post 21) uses three swap routines. One for two items, one for three and one for four items. We can change the comparisons expressions and the swap routines with dummy routines that hold only a raiseevent command and we can make the realy good and fast DPQS sorting routine versatile. Using an array for index is not always a good idea (you have to lock the data), but for these examples are often a good choice.
As for fatty code in myDoc class: This class is used here for the need of a document editor. Some day me or any of my small students (I teach children how to use software) can make a better code using a class.
So it is nice to do a "competition" with you Olaf...this is a Greek way to "good fight", or as we can say "Ευ αγωνίζεσθαι".
George
Code:
Const NORM_IGNORECASE As Long = &H1 'Ignore case.
Const NORM_IGNOREKANATYPE As Long = &H40 'Do not differentiate between Hiragana and Katakana characters. Corresponding Hiragana and Katakana characters compare as equal.
Const NORM_IGNORENONSPACE As Long = &H2 'Ignore nonspacing characters.
Const NORM_IGNORESYMBOLS As Long = &H4 'Ignore symbols.
Const NORM_IGNOREWIDTH As Long = &H8 'Do not differentiate between a single-byte character and the same character as a double-byte character.
Const SORT_STRINGSORT As Long = &H1000 'Treat punctuation the same as symbols.
Declare Function CompareStringW Lib "kernel32.dll" ( _
ByVal Locale As Long, _
ByVal dwCmpFlags As Long, _
ByVal lpString1 As Long, _
ByVal cchCount1 As Long, _
ByVal lpString2 As Long, _
ByVal cchCount2 As Long) As Long
Public Function myCompEq(a$, b$) As Long
dim clid ' leave it zero
myCompEq = CompareStringW(cLid, 0, StrPtr(a$), -1, StrPtr(b$), -1)
End Function
Ok - I'm just way too busy these days and I've wanted to add a sort to your code and see how it performs. Just no time to do it...
Since you mention you have students I'll post the sort code and if you all think it's worthy include it in your timings.
I believe this is a Shell Sort (could be wrong - I've had it in my "tool box" since 1980 - back when I coded BASIC on PDP-11 minicomputers).
With that said, it has GOTO statements. First challenge would be to get this code into the realm of proper conditional statements.
I just copied it from a C++ routine of mine. Second challenge is to get it into a VB6-ish syntax. Shouldn't be that hard - it's a simple series of logic.
Don't get overwhelmed by the key compare code. It's just a -1,0,1 value for <, = or >. And it's got a hack for keeping the list stable - not really needed.
And it's not actually moving the data when sorting, it's creating a POINTER array that is in sorted order. Also, not really needed.
Code:
int s1 = nKeywordskt;
int s2 = s1;
int s3 = 0, s4 = 0, s5 = 0, s6 = 0;
int a = 0;
GP_SP_S1:
s1 = s1 / 2;
if (s1 == 0) {
goto GP_SP_S5;
}
s3 = s2 - s1;
s4 = 1;
GP_SP_S2:
s5 = s4;
GP_SP_S3:
s6 = s5 + s1;
a = mxstrcmp(strSearch, smarkerskt[sortptrs[s5-1]], emarkerskt[sortptrs[s5-1]], smarkerskt[sortptrs[s6-1]], emarkerskt[sortptrs[s6-1]]);
if (a == 0) {
if (sortptrs[s5-1] < sortptrs[s6-1]) {
a = -1;
} else {
a = 1;
}
}
if (a <= 0) {
goto GP_SP_S4;
}
j = sortptrs[s5-1];
sortptrs[s5-1] = sortptrs[s6-1];
sortptrs[s6-1] = j;
s5 = s5 - s1;
if (s5 >= 1) {
goto GP_SP_S3;
}
GP_SP_S4:
s4 = s4 + 1;
if (s4 > s3) {
goto GP_SP_S1;
}
goto GP_SP_S2;
GP_SP_S5:
s1 = 0; // dummy line
*** Read the sticky in the DB forum about how to get your question answered quickly!! ***
Please remember to rate posts! Rate any post you find helpful - even in old threads! Use the link to the left - "Rate this Post".
I see your changes; You do a copy of data from linked list to a string array and the over time is due to link fixation on the last stage. We have a splendid speedy algo, but with one bad thing (not bad always, in this case is), we copy the data.
No, we dont...
if you look more carefully at the code I used in the updated Sort-Routines,
I've used TetParaGraphKey instead of TextParagraph to provide the comparison-
content in Arr() ... (and TetParaGraphKey respects your mKeyStart-Private-Variable)...
Code:
mKeystart = IIf(KeyStart < 0, 1, KeyStart)
For i = 1 To UBound(Ind)
Ind(i) = DocParaNext(Ind(i - 1))
Arr(i) = TextParagraphKey(Ind(i))
Next i
If order1 <= 0 Then order1 = 1
If order2 <= 0 Then order2 = i - 1
DualPivotQuickSort Arr, Ind, order1, order2
For i = 1 To UBound(Ind)
DocParaNext(Ind(i - 1)) = Ind(i)
DocParaBack(Ind(i)) = Ind(i - 1)
Next i
DocParaNext(Ind(UBound(Ind))) = 0
DocParaBack(0) = Ind(UBound(Ind))
Originally Posted by georgekar
If we use string compare in place, by using pointers, then we have no string transfer, ...
Feel free to switch back (using CompareStringW or whatever) to your former approach -
but I can tell you already, that this will not beat the performance of the modification as
it is in my latest update on your Doc-Class...
Originally Posted by georgekar
I see that you remove the DPQS from myDoc class, and also the needed functions to operate the list. This changed routine (and missing from your last example, but is in mine in post 21) uses three swap routines.
These are not needed anymore - I really thought I made a point with my modification,
which incorporated the *original* (indirect) Sort-Routines from the *.bas module,
which are already generic enough with their indirection-array, to be applied to nearly
all scenarios - without the need to reinvent "new Swap-Routines" for them...
Originally Posted by georgekar
As for fatty code in myDoc class: This class is used here for the need of a document editor.
I've seen your stuff there - and it's not really how a TextBox-implementation should be done -
for a more efficient one, you can always look at the implementation of the cwTextBox-widget
in the GitHub vbWidgets-project (Link is on my site vbRichClient.com).
I guess you want to implement your own WidgetSet - but your current encapsulation of "everything"
in only one single "universal control" (in conjunction with your huge Doc-Class) is not really helpful
along your way - you will loose yourself at some point in time in that huge single code-chunk,
not going any further - if I may give a bit of advice - split it up into more (smaller) classes, which
can stand on their own.
A framework needs to be worked-up as a "stack of useful generic routines" - small pieces you
build upon (in different Classes, which have their usage also elsewhere).
Originally Posted by georgekar
So it is nice to do a "competition" with you Olaf...this is a Greek way to "good fight", or as we can say "Ευ αγωνίζεσθαι".
Glad you're taking no offense - wish this kind of "sports-spirit" would be more common
in the forum here.
@szlamany
As I see you use smarkerskt[] for the start of the string and amarkerskt[] for the end. This means that you have somewhere in memory the actual non movable strings. I like goto...A goto may have one of two meanings...to skip code or to restart code.
See my language and environment here. M2000 interpreter has GOTO and can use labels as names with : and numbers with 5 digits (without . But you can't use underscore..(but i can update the language it if you like)
I make now a COMPARE function to compare string vars only (no expressions) and I make your code to M2000. Also I can make it for vb6 and we can see how speedy is..
@Schmidt,
You use TextParagraphKey, for me this is reading of the data and copy all (if keyStart=1), so you copy entire list in a fresh string array. That is no bad at all. You going back to your idea. My idea was to slow down everything to see what happen when a big load is there.
As for my bloatware: This is my piece of work and any criticism is allowed, especially from someone how have spend time to make own same and better work. As you know every piece of code has own limitations. So for my code I know exactly the limitations, and the ugly things like the size of code. For the size I have no problem...for text, only from the vb scope, the compiler produce a very long machine code with thousands of bytes.. I use one fine tuning user control (and now the latest version has no shapes on it, it is a necked user control). And yes I split the functionality to some classes, one for textboxes, other for textviewer and edit, a nice one for drop down list. My basic scope was to not use any control from MS, and not needing for any com library for subclassing. So the only think that can "destroy" the happiness of good working is the break off vb6 runtime dll and maybe the changes of OS functions. Also my code is open source.
off topic..................here
You can find the implementation of my user control here in the M2000 environment. I use it for text editor, listbox, dropdown listbox with autocomplete function, textboxes, command buttons, and many other things, in forms that zoommed nicely. I use my own file selector, folder selector, font and color selector, and own msgbox. This language is for education for children and that children can open the file selector without delete anything (my file selectors do only that...select files. I can't understand why Microsoft give such rights to anyone to delete anything, or move anything, or run anything from a file selector...). And of course these selectors can be zoomed (and expanded if check that in setup). As you can understand my control is not a replacement of MS controls, but have things to offer that MS controls didn't have. So anyone can freely use it, or expand it as he like.
I have the vbRichClient and the example of treetest. Very good. Some day I would like to put it in M2000...to open own windows but not this moment. I have to finish the help file. Where is the help file for vbRichClient? Is there any documentation?
Where is the help file for vbRichClient? Is there any documentation?
You can get latest (31-Oct-2014) CHM manual of vbRichClient5 and vbWidgets at this link: http://cyberactivex.com/UnicodeTutor...m#vbRichClient
Between the CHM files and the many demos you should be able to figure out how to use it.
Public Sub QSort2(ByRef key_arr() As Long, L As Long, R As Long) '目前最快的qsort
Dim i As Long, j As Long
Dim x As Long, Swap As Long
Const k As Long = 60
If R - L <= k Then
For i = L + 1 To R
x = key_arr(i)
For j = i - 1 To L Step -1
If key_arr(j) <= x Then Exit For
key_arr(j + 1) = key_arr(j)
Next
key_arr(j + 1) = x
Next
Else
x = key_arr((L + R) \ 2)
i = L
j = R
Do While i <= j
Do While key_arr(i) < x
i = i + 1
Loop
Do While key_arr(j) > x
j = j - 1
Loop
If i <= j Then
Swap = key_arr(i)
key_arr(i) = key_arr(j)
key_arr(j) = Swap
i = i + 1
j = j - 1
End If
Loop
'递归方法
If L < j Then
Do While key_arr(j) = x
j = j - 1
If j = L Then Exit Do
Loop
Call QSort2(key_arr, L, j)
End If
If i < R Then
Do While key_arr(i) = x
i = i + 1
If i = R Then Exit Do
Loop
Call QSort2(key_arr, i, R)
End If
End If
End Sub
Option Explicit
#Const UseMSVCRT = 1
#If UseMSVCRT Then
'/***
'*qsort(base, num, wid, comp) - quicksort function for sorting arrays
'*
'*Purpose:
'* quicksort the array of elements
'* side effects: sorts in place
'* maximum array size is number of elements times size of elements,
'* but is limited by the virtual address space of the processor
'*
'*Entry:
'* char *base = pointer to base of array
'* size_t num = number of elements in the array
'* size_t width = width in bytes of each array element
'* int (*comp)() = pointer to function returning analog of strcmp for
'* strings, but supplied by user for comparing the array elements.
'* it accepts 2 pointers to elements.
'* Returns neg if 1<2, 0 if 1=2, pos if 1>2.
'*
'*Exit:
'* returns void
'*
'*Exceptions:
'* Input parameters are validated. Refer to the validation section of the function.
'*
'*******************************************************************************/
Private Declare Function CallWindowProc Lib "user32.dll" Alias "CallWindowProcA" (ByVal lpPrevWndFunc As Long, ByVal hwnd As Long, ByVal msg As Long, ByVal wParam As Long, ByVal lParam As Long) As Long
Private Declare Sub CopyMemory Lib "kernel32.dll" Alias "RtlMoveMemory" (ByRef Destination As Any, ByRef Source As Any, ByVal Length As Long)
Private Declare Function LoadLibrary Lib "kernel32.dll" Alias "LoadLibraryA" (ByVal lpLibFileName As String) As Long
Private Declare Function FreeLibrary Lib "kernel32.dll" (ByVal hLibModule As Long) As Long
Private Declare Function GetProcAddress Lib "kernel32.dll" (ByVal hModule As Long, ByVal lpProcName As String) As Long
Private m_bCode(255) As Byte, m_hMod As Long, m_lpFunc As Long
Private m_lpObjPtr As Long, m_nUserData As Long
#End If
Public Function Compare(ByVal Index1 As Long, ByVal Index2 As Long, ByVal nUserData As Long) As Long
'default implementation (???)
If Index1 < Index2 Then Compare = -1 Else _
If Index1 > Index2 Then Compare = 1 Else Compare = 0
End Function
Friend Sub QuickSort(idxArray() As Long, ByVal nStart As Long, ByVal nEnd As Long, Optional ByVal obj As ISort2, Optional ByVal nUserData As Long, Optional ByVal nLimit As Long = 8)
'///check
If nEnd - nStart <= 1 Then Exit Sub
If obj Is Nothing Then Set obj = Me
'///
#If UseMSVCRT Then
If m_lpFunc Then
m_lpObjPtr = ObjPtr(obj)
m_nUserData = nUserData
CallWindowProc VarPtr(m_bCode(0)), VarPtr(idxArray(nStart)), nEnd - nStart + 1, m_lpFunc, 0
Exit Sub
End If
#Else
'////////////////////////////////TODO:translate qsort.c into VB
Dim i As Long, j As Long, k As Long 'temp
Dim nMid As Long '/* points to middle of subarray */
Dim lpStart As Long, lpEnd As Long '/* traveling pointers for partition step */
Dim nSize As Long '/* size of the sub-array */
Dim nStartStack(31) As Long, nEndStack(31) As Long, nStack As Long '/* stack for saving sub-array to be processed */
'/* this entry point is for pseudo-recursion calling: setting
' lo and hi and jumping to here is like recursion, but stkptr is
' preserved, locals aren't, so we preserve stuff on the stack */
Recurse:
'size = (hi - lo) / width + 1; /* number of el's to sort */
nSize = nEnd - nStart + 1
'/* below a certain size, it is faster to use a O(n^2) sorting method */
If nSize <= nLimit Then
'shortsort
If nSize > 1 Then
Do
lpStart = nStart
i = idxArray(lpStart)
For lpEnd = nStart + 1 To nEnd
j = idxArray(lpEnd)
If obj.Compare(j, i, nUserData) > 0 Then lpStart = lpEnd: i = j
Next lpEnd
If lpStart < nEnd Then idxArray(lpStart) = idxArray(nEnd): idxArray(nEnd) = i
nEnd = nEnd - 1
Loop While nEnd > nStart
End If
Else
' /* First we pick a partitioning element. The efficiency of the
' algorithm demands that we find one that is approximately the median
' of the values, but also that we select one fast. We choose the
' median of the first, middle, and last elements, to avoid bad
' performance in the face of already sorted data, or data that is made
' up of multiple sorted runs appended together. Testing shows that a
' median-of-three algorithm provides better performance than simply
' picking the middle element for the latter case. */
' mid = lo + (size / 2) * width; /* find middle element */
nMid = nStart + nSize \ 2
'
' /* Sort the first, middle, last elements into order */
' if (__COMPARE(context, lo, mid) > 0) swap(lo, mid, width);
i = idxArray(nStart): j = idxArray(nMid)
If obj.Compare(i, j, nUserData) > 0 Then idxArray(nStart) = j: idxArray(nMid) = i
' if (__COMPARE(context, lo, hi) > 0) swap(lo, hi, width);
i = idxArray(nStart): j = idxArray(nEnd)
If obj.Compare(i, j, nUserData) > 0 Then idxArray(nStart) = j: idxArray(nEnd) = i
' if (__COMPARE(context, mid, hi) > 0) swap(mid, hi, width);
i = idxArray(nMid): j = idxArray(nEnd)
If obj.Compare(i, j, nUserData) > 0 Then idxArray(nMid) = j: idxArray(nEnd) = i
'
' /* We now wish to partition the array into three pieces, one consisting
' of elements <= partition element, one of elements equal to the
' partition element, and one of elements > than it. This is done
' below; comments indicate conditions established at every step. */
'
' loguy = lo;
' higuy = hi;
lpStart = nStart
lpEnd = nEnd
'
' /* Note that higuy decreases and loguy increases on every iteration,
' so loop must terminate. */
' for (;;) {
Do
' /* lo <= loguy < hi, lo < higuy <= hi,
' A[i] <= A[mid] for lo <= i <= loguy,
' A[i] > A[mid] for higuy <= i < hi,
' A[hi] >= A[mid] */
'
' /* The longd loop is to avoid calling comp(mid,mid), since some
' existing comparison funcs don't work when passed the same
' value for both pointers. */
i = idxArray(nMid)
' if (mid > loguy) {
' do {
' loguy += width;
' } while (loguy < mid && __COMPARE(context, loguy, mid) <= 0);
' }
If nMid > lpStart Then
Do
lpStart = lpStart + 1
j = idxArray(lpStart)
If lpStart >= nMid Then Exit Do
Loop While obj.Compare(j, i, nUserData) <= 0
End If
' if (mid <= loguy) {
' do {
' loguy += width;
' } while (loguy <= hi && __COMPARE(context, loguy, mid) <= 0);
' }
If nMid <= lpStart Then
Do
lpStart = lpStart + 1
If lpStart > nEnd Then Exit Do
j = idxArray(lpStart)
Loop While obj.Compare(j, i, nUserData) <= 0
End If
'
' /* lo < loguy <= hi+1, A[i] <= A[mid] for lo <= i < loguy,
' either loguy > hi or A[loguy] > A[mid] */
'
' do {
' higuy -= width;
' } while (higuy > mid && __COMPARE(context, higuy, mid) > 0);
Do
lpEnd = lpEnd - 1
k = idxArray(lpEnd)
If lpEnd <= nMid Then Exit Do
Loop While obj.Compare(k, i, nUserData) > 0
'
' /* lo <= higuy < hi, A[i] > A[mid] for higuy < i < hi,
' either higuy == lo or A[higuy] <= A[mid] */
'
' if (higuy < loguy)
' break;
If lpEnd < lpStart Then Exit Do
'
' /* if loguy > hi or higuy == lo, then we would have exited, so
' A[loguy] > A[mid], A[higuy] <= A[mid],
' loguy <= hi, higuy > lo */
'
' swap(loguy, higuy, width);
If lpEnd > lpStart Then idxArray(lpStart) = k: idxArray(lpEnd) = j
'
' /* If the partition element was moved, follow it. Only need
' to check for mid == higuy, since before the swap,
' A[loguy] > A[mid] implies loguy != mid. */
'
' if (mid == higuy)
' mid = loguy;
If nMid = lpEnd Then nMid = lpStart
'
' /* A[loguy] <= A[mid], A[higuy] > A[mid]; so condition at top
' of loop is re-established */
' }
Loop
'
' /* A[i] <= A[mid] for lo <= i < loguy,
' A[i] > A[mid] for higuy < i < hi,
' A[hi] >= A[mid]
' higuy < loguy
' implying:
' higuy == loguy-1
' or higuy == hi - 1, loguy == hi + 1, A[hi] == A[mid] */
'
' /* Find adjacent elements equal to the partition element. The
' longd loop is to avoid calling comp(mid,mid), since some
' existing comparison funcs don't work when passed the same value
' for both pointers. */
'
' higuy += width;
lpEnd = lpEnd + 1
' if (mid < higuy) {
' do {
' higuy -= width;
' } while (higuy > mid && __COMPARE(context, higuy, mid) == 0);
' }
i = idxArray(nMid)
If nMid < lpEnd Then
Do
lpEnd = lpEnd - 1
If lpEnd <= nMid Then Exit Do
Loop While obj.Compare(idxArray(lpEnd), i, nUserData) = 0
End If
' if (mid >= higuy) {
' do {
' higuy -= width;
' } while (higuy > lo && __COMPARE(context, higuy, mid) == 0);
' }
If nMid >= lpEnd Then
Do
lpEnd = lpEnd - 1
If lpEnd <= nStart Then Exit Do
Loop While obj.Compare(idxArray(lpEnd), i, nUserData) = 0
End If
'
' /* OK, now we have the following:
' higuy < loguy
' lo <= higuy <= hi
' A[i] <= A[mid] for lo <= i <= higuy
' A[i] == A[mid] for higuy < i < loguy
' A[i] > A[mid] for loguy <= i < hi
' A[hi] >= A[mid] */
'
' /* We've finished the partition, now we want to sort the subarrays
' [lo, higuy] and [loguy, hi].
' We do the smaller one first to minimize stack usage.
' We only sort arrays of length 2 or more.*/
'
' if ( higuy - lo >= hi - loguy ) {
If lpEnd - nStart >= nEnd - lpStart Then
' if (lo < higuy) {
' lostk[stkptr] = lo;
' histk[stkptr] = higuy;
' ++stkptr;
' } /* save big recursion for later */
If nStart < lpEnd Then
nStartStack(nStack) = nStart
nEndStack(nStack) = lpEnd
nStack = nStack + 1
End If
' if (loguy < hi) {
' lo = loguy;
' goto recurse; /* do small recursion */
' }
If lpStart < nEnd Then
nStart = lpStart
GoTo Recurse
End If
' }
Else
' else {
' if (loguy < hi) {
' lostk[stkptr] = loguy;
' histk[stkptr] = hi;
' ++stkptr; /* save big recursion for later */
' }
If lpStart < nEnd Then
nStartStack(nStack) = lpStart
nEndStack(nStack) = nEnd
nStack = nStack + 1
End If
'
' if (lo < higuy) {
' hi = higuy;
' goto recurse; /* do small recursion */
' }
If nStart < lpEnd Then
nEnd = lpEnd
GoTo Recurse
End If
' }
End If
End If
'/* We have sorted the array, except for any pending sorts on the stack.
' Check if there are any, and do them. */
nStack = nStack - 1
If nStack >= 0 Then
nStart = nStartStack(nStack)
nEnd = nEndStack(nStack)
GoTo Recurse '/* pop subarray from stack */
End If
'else
' return; /* all subarrays done */
'////////////////////////////////
#End If
End Sub
#If UseMSVCRT Then
Private Sub Class_Initialize()
Dim s As String
'///
m_hMod = LoadLibrary("msvcrt.dll")
m_lpFunc = GetProcAddress(m_hMod, "qsort")
'///
s = "89 E0 E8 00 00 00 00 83 04 24 15 6A 04 FF 70 08" + _
"FF 70 04 FF 50 0C 83 C4 10 C2 10 00 6A 00 89 E0" + _
"8B 15 ObjPtr 50 FF 35 UserData 8B 48 0C" + _
"8B 40 08 FF 31 FF 30 8B 0A 52 FF 51 1C 58 C3"
s = Replace(s, "ObjPtr", ReverseHex(VarPtr(m_lpObjPtr)))
s = Replace(s, "UserData", ReverseHex(VarPtr(m_nUserData)))
CodeFromString s, m_bCode
End Sub
Private Sub Class_Terminate()
FreeLibrary m_hMod
End Sub
Private Sub CodeFromString(ByVal s As String, ByRef b() As Byte)
Dim m As Long, i As Long
s = Replace(s, " ", "")
s = Replace(s, ",", "")
m = Len(s) \ 2
For i = 0 To m - 1
b(i) = Val("&H" + Mid(s, i + i + 1, 2))
Next i
End Sub
Private Function ReverseHex(ByVal n As Long) As String
Dim s As String
s = Right("00000000" + Hex(n), 8)
ReverseHex = Mid(s, 7, 2) + Mid(s, 5, 2) + Mid(s, 3, 2) + Mid(s, 1, 2)
End Function
#End If
This QuickSort by someone at vbGood is the most fast quick sort i have ever seen
if sorting a string array, should use string pointer to swap, and change the first parameter to string()
Code:
Public Sub QSort2(ByRef key_arr() As Long, ByVal l As Long, ByVal r As Long)
Dim i As Long, j As Long
Dim x As Long, Swap As Long
Const k As Long = 60
If r - l <= k Then
For i = l + 1 To r
x = key_arr(i)
For j = i - 1 To l Step -1
If key_arr(j) <= x Then Exit For
key_arr(j + 1) = key_arr(j)
Next
key_arr(j + 1) = x
Next
Else
x = key_arr((l + r) \ 2)
i = l
j = r
Do While i <= j
Do While key_arr(i) < x
i = i + 1
Loop
Do While key_arr(j) > x
j = j - 1
Loop
If i <= j Then
Swap = key_arr(i)
key_arr(i) = key_arr(j)
key_arr(j) = Swap
i = i + 1
j = j - 1
End If
Loop
If l < j Then
Do While key_arr(j) = x
j = j - 1
If j = l Then Exit Do
Loop
Call QSort2(key_arr, l, j)
End If
If i < r Then
Do While key_arr(i) = x
i = i + 1
If i = r Then Exit Do
Loop
Call QSort2(key_arr, i, r)
End If
End If
End Sub
by the way, i claim that with no offense.
and i have added words like "i have ever seen"
so do not judge me a lot, i only wanna share what i think is the best.
if u guys have better option, it will be nice if u share it to me.
by the way, i claim that with no offense.
and i have added words like "i have ever seen"
so do not judge me a lot, i only wanna share what i think is the best.
if u guys have better option, it will be nice if u share it to me.
I'd say, that the Dual-Pivot is the better option, when you want a "general purpose algo" - and on my machine (with 2Mio 32Bit-Long-Arrays)
it is only ~10% slower (223msec) than the QSort2 you've posted (206msec), which is simply a naive QS, extended by the usual insertion-sort at the top).
Please read my post #20 again, where I've written about the amount of comparisons ...
(the Dual-Pivot is the algo which needs the least comparisons to achieve a sorted result on the most common case with random data).
So, with String-Data or when CallBack-Delegations to a Comparer-function are used, the DualPivot is hard to beat.
If you have only Integer-Arrays to sort (easy to compare, easy to swap even ByValue),
the choosen algorithm does not really make that much of a difference, becaue:
- 1Mio random 32Bit-Integers will be sorted in about 100-200msec on current CPUs (with any QuickSort)
- whereas, when 1Mio random Strings will take 1.5-3seconds (and the User has to wait about factor 15 longer for the result) -
. algorithms which perform less comparisons can shape off some time "you really feel".
I'd suggest that you make a few tests with String-Arrays (which do a pointer-swap, or use an indirect sort).
Olaf you once showed me how to use StrCmpLogicalW(StrPtr(S1),StrPtr(S2)) with a standard QuickSort.
I would now like to use the DualPivot-Quicksort and have tried replacing all the comparisons (If M1<M2) etc with the StrCmpLogicalW equivalent but it is VERY slow. Can you show how you would do it please.






 Reply With Quote
Reply With Quote